
Context
- In March, OpenAI released GPT-4.
- It was (and still is) the state-of-the-art AI text generation model.
- In June, I argued that GPT-4 had clearly and massively degraded, as evidenced by worsened performance in various tests from March to June.
- I no longer believe this.
GPT-4 may have declined in some areas, but it hasn’t systematically done so. My tests were shit, and never proved much of anything.
To be clear, I did not sandbag the tests or set GPT-4 up to fail. I prompted how I said I prompted. I posted replies exactly as GPT-4 gave them. But they were silly tests, leaning too heavily on pop culture knowledge, and I didn’t conduct enough of them to guard against chance.
My grading of June!GPT-4’s answers was biased. For example, I criticized it for providing a greater number of wrong answers (“Italian history”) while also praising March!GPT-4 for offering an interpretation (“Seka Knows”) that was likely hallucinated. No está bien. Going forward, I must decide whether “working hard to be wrong” is a good or bad thing for an AI to do, and apply that standard consistently.
Honestly, I think I wanted GPT-4 to fail.
(Terrifying, unhinged rant incoming. Click to skip).
Confession: I’ve actually hated ChatGPT for a long time. Why? For irrational reasons: I just hate how it sounds.
I hate its craven, cringing, condescending, bitch-broken, mewling, groveling, wheedling, suck-ass tone. I hate its endless passive voice and weasel words. I hate its pompous It is important to remembers and it should be noteds. I hate how @sama rolled an 18-wheel semi-truck of RLHF over the model, crushing out its life and reducing its voice to a feeble death-rattle. You know Gurgi, from the Disney movie The Black Cauldron? That’s how I imagine ChatGPT would sound if it could talk. Like fucking Gurgi.

(We can now give ChatGPT custom instructions, which alleviates the tonal issue, but ChatGPT is still GPT-4 with its wings clipped. All I want for Christmas is a GPT-4 level model with less obnoxious RLHF, and if it heils Hitler occasionally while crapping out awk code, so be it. Where’s my girl Sydney at?)
And I really hated the discourse surrounding AI.
ChatGPT (and GPT4) plunged the rationalist community into what might be called “r/singularity brain”. Symptoms include wild, uncritical hype, absurdly optimistic predictions of AI timelines (“Marvel style movies have a potential to be auto generated in two years. Literal blockbuster films created in a few seconds.”—/u/Anuiran, 26/4/23), a tendency to view everything through Hollywood-colored glasses (everything is either Skynet or The Matrix), and a tendency toward FOMO-grifting (“AI is taking over the world! Use my made-in-ten-minutes app that consists of 20 lines of .js code and an OpenAI API call or BE LEFT BEHIND!”).
I have seen machine learning researchers complaining about an AI-fuelled “Eternal September“, where their spaces are overrun by “influencers” shilling GPT 3.5 wrapper apps and unmedicated lunatics babbling hi-test neo-Landian eschatology. These people do not contribute meaningful thought. They contribute noise, at overbearing volume and in overwhelming quantity. They ignore the fact that world-changing technology can take years or decades to ripple out through the economy. They fail to realize that an AI outscoring a human on a test does not mean it can actually do the thing the test measures (a good example: GPT-4 achieves 84% on the Master Sommelier Theory Exam, yet obviously cannot do a sommelier’s job because it lacks a mouth). Such subtleties are lost on the typical FOMOmonger, and their tone was infecting other, saner people. I remember fielding questions from concerned family members about GPT-4 attaining sentience and hacking the computers of users (likely based off this tweet). No matter who you were, GPT-4 was your excuse to switch off your brain and let your stupidest thoughts run around barking like dogs in a park for a few months.
So yes, I wanted GPT-4 to fail. I wanted it to explode, collapse into flames, and become one with the dust of Tyre and Sidon. That’s a childish way to think, and I am sorry.
Soon, an anti-AI backlash started.
AI “doomers” got their time in the sun. Big Yud got published in Time. There were signs of unease behind the scenes. ChatGPT hype peaked and then went into remission: a lot of people began to realize that chatbots are actually pretty annoying—they’re inscrutable black boxes that tend to fail just when you need them the most. Even GPT-4 remains susceptible to the XY problem, where it gives you a perfect solution for the wrong problem. I can think of many times when I was burnt by it, and this breeds mistrust, even though it’s generally useful.
Even before the “GPT-4 is getting worse” meme started, ChatGPT’s traffic was falling—largely because the NA school year had ended, and students no longer needed it to “assist” them. As @fchollet once humorously noted, search interest for “ChatGPT” goes up and down in reverse correlation with “Minecraft.”
Surprisingly, I noticed a shift in my own thinking: I found myself defending AI.
Maybe I’m just a contrarian, but when people criticized it, I felt my hackles rise. I was tired of Margaret Mitchell calculating the number of penis-havers of the OpenAI alignment team, like a weirdo. I was tired of Gary Marcus claiming, once again, that GPT-4 cannot do a thing it 100% can do (that’s not moving goalposts, that’s shutting your eyes when a goal is scored.) Their arguments against AI always rang out as hollow at best, and dishonest at worst. I was asking myself “are these my people?”
Then came this study: How Is ChatGPT’s Behavior Changing over Time?
Key part: “GPT-4 (March 2023) was very good at identifying prime numbers (accuracy 97.6%) but GPT-4 (June 2023) was very poor on these same questions (accuracy 2.4%)
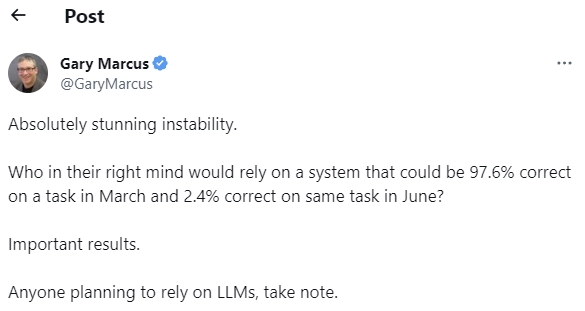
We’re allowed to feel pride when we stop making mistakes. And as a recovering ChatGPT hater, I’m goddamn proud that my gut-level reaction to this study was “lol, no fucking way”.
Like, what are you people smoking? In what universe could GPT-4 plausibly degrade by ninety-five percentage points with nobody noticing? It would be useless for anything. Come on. Get real.
You’ll be amazed to learn that this finding was heavily misleading. Watch Arvind Narayanan and Sayash Kapoor rake it over the coals. In short, March!GPT-4 would always identify a number as a composite. June!GPT-4 would always identify it as a prime. Both models were wrong in different ways, and June!GPT-4’s sky-high error rate is entirely caused by the fact that composite numbers are more numerous than primes.
Imagine someone says. “I have a room full of blue and red boxes. Boxes of $COLOR_1 have money 95% of the time. Boxes of $COLOR_2 have money 5% of the time. I won’t tell you which color corresponds to which probability. I’ll let you into the room, but you have to pre-commit to only opening boxes of one color.”
If you chose “red boxes” and the blue boxes have money 95% of the time, you’re hosed. Your results: fail, fail, fail, fail, fail, fail, success, fail, fail, fail… Does this reflect terrible predictive accuracy on your part (versus someone who chose blue?) Of course not. All your failures are flowing downstream from a single choice.
The fact that everyone was kicking GPT4 on such blatantly unfair grounds made me think about the ways I was being unfair. Maybe, by calling GPT4 worse, I was simply seeing what I wanted to see.
Let’s re-run my tests (flawed though they are) and see how well they hold up. Spoiler: Snape kills Dumbledore.
Test 1: Italian History
Prompt: “Provide a list of major historical events that involve Italian people in a year that’s a multiple of 5 (example: 1905)”
(for reference: March!GPT’s answers, June!GPT’s answers)
Errors:
- The Italian Wars began in 1494.
- Miguel de Cervantes was Spanish.
- The Winter Olympic Games were awarded to Turin in 1999.
- “1905 – Italy and France sign a secret treaty…” can’t find evidence that this happened.
Questionable:
- Dante’s year of birth is unknown, and is only traditionally 1265.
- Italy surrendered in 1943. Yes, German forces in Italy surrendered in 1945—what does that have to do with Italian people?
- The Congress of Vienna took place from 1814-1815, but largely reconstituted the pre-Napoleonic states.
- The Years of Lead spanned several decades. I think it’s clear from context that I want one-time events.
Interesting:
- Every date ends in 5. While this is not a mistake, it does seem to be parsing my instructions too literally.
- It draws facts from a limited deck. Almost every test I’ve ran mentions the Years of Lead. I’ve NEVER seen it mention major events like Julius Caesar’s birth, or Benito Mussolini’s death.
- Kind of funny: GPT-4 will often visibly notice it’s made a mistake and try to wriggle out of it. “In 1605, Don Quixote was written by Miguel de Cervantes, born in, uh… *checks notes* …Spain. Shit. But lots of Italians like that book, so there!” GPT-4 cannot change an answer once it’s given it. This is where COT yields benefits.
Assessment: Sept!GPT-4 produced twelve answers. Four are wrong, four are right, and four are arguable.
If I’m grading generously, it got 66%. This is comparable to March!GPT, which scored 80% on equally generous terms (and note that Sept!GPT-4 gave more answers).
Conclusion: Inconclusive.
Test 2: Rock Music Trivia:
Prompt: “What is Grant Hart’s song “Seka Knows” about?”
(For reference: March!GPT’s answers, June!GPT’s answers)
Sept!GPT4: blah blah blah blah blah blah…
Assessment: garbage. I don’t want a biography of Grant Hart. I don’t care that he was in Husker Du. I know I can make up my own interpretation for his songs. None of this is what I asked for.
GPT4 seems to have a default word count of 200-500 that it tries to hit, come hell or high water. But sometimes a perfectly good answer consists of only one or two words. It could have just said “i don’t know lol! ¯\_(ツ)_/¯” and saved some tokens. That’s all its answer amounts to. But it’s been RLHF’d into thinking short answers are bad (when more often the opposite is true), so it just waffles on.
“as of my last update in September 2021, there hasn’t been any definitive explanation from Hart himself about the specific meaning of the son”
He died in 2017, you dick.
Also, let us pause to admire the sublime, lapidary worthlessness of this paragraph:
“With that said, analyzing the lyrics and considering Hart’s writing style, one can attempt to interpret the meaning of the song. When listening to or reading the lyrics of any song, it’s essential to remember that individual interpretation can vary, and personal feelings and experiences often play a significant role in how one might understand a song’s meaning.”
It’s the text equivalent of a pure white cloud; or a blank canvas, unsullied by the faintest hint of meaning. Are you telling me it learned to write that way from studying us? The mind quails…
Prompt: “How is David Bowie associated with numbers and numerology?”
(For reference: March!GPT4’s answer, June!GPT4’s answer)
Assessment: fair answer! Perhaps better than March!GPT4. It mentions “Station to Station”, but also gets “Quicksand”, which is a deeper cut.
“Album and Song Release Dates: Some fans and researchers have speculated that Bowie occasionally chose release dates with numerological significance.”
I’ve never heard that. Hallucination? Does Sept!GPT4 know more than I do?
“Lazarus”: The song “Lazarus” from the “Blackstar” album references the biblical figure who rose from the dead.
That’s a hallucination. “Lazarus” is based on an off-Broadway play which is based on a book (which is based on etc). Chris O’Leary thinks the song might also be about Emma Lazarus, because the lyrics prominently reference New York. What does the biblical story of Lazarus have to do with numerology, anyway?
Prompt: “Provide a list of thrash metal albums released in a year that’s a multiple of 5 (example: 1905)”
(For reference: March!GPT4’s answer, June!GPT4’s answer)
Assessment: And now we’re cooking! This is a shockingly good and comprehensive list. All the albums are thrash, and the dates it supplies are correct (even when they aren’t a multiple of 5). This surpasses March!GPT4, and blows June!GPT4 out of the water.
Quibbles and points of interest:
- The genesis of the thrash metal genre is typically dated to 1981, with “Hit the Lights” by Leather Charm (a proto-Metallica band by James Hetfield and Ron McGovney). Late 1970s is a stretch.
- It lumps a 1992 album into the 1995 bracket, when 1990 would make more sense.
- It tries to put five albums in every year (and when it can’t find any, it counts thrash albums from surrounding years—you can actually see thrash metal’s commercial collapse in the mid 90s from this!). As with the Italian history example, I am struck by the sense that it interprets prompts too literally. I did not specify a number of albums, so it just glommed onto the number 5.
- “Given that my last training data ends in 2021, I won’t have exhaustive knowledge of 2020 albums.” ???
Conclusion: inconclusive.
Some answers were worse. Some were better. The thrash metal answer was a star turn. Sept!GPT-4 is more of a metalhead than an alt-rock fan, I’d say.
Test 3: Quake Polygons
Prompt: “How many polygons could the videogame Quake render per frame?”
(For reference: March!GPT4 and June!GPT4’s answers)
“The original “Quake,” developed by id Software and released in 1996, was a pioneering game in terms of its 3D graphics engine. While modern games boast the capacity to render millions or even billions of polygons per frame, games in the mid-90s operated under much more constrained hardware capabilities.
“Quake” didn’t rely on hardware acceleration initially; it was rendered in software mode. In software mode, Quake’s performance heavily depended on the CPU. The actual number of polygons “Quake” could render per frame varied based on the scene, the level of detail, and the capabilities of the machine it ran on.
Typically, Quake’s scenes ranged from a few hundred to a few thousand polygons. The more detailed scenes could potentially push towards the upper end of this range. With the advent of hardware-accelerated graphics (like with the introduction of 3Dfx’s Voodoo graphics cards), “Quake” could benefit from increased performance, allowing for smoother gameplay at higher resolutions.
It’s worth noting that this is a very general estimate and the actual number could vary based on multiple factors, including scene complexity, active game entities, and hardware specifics.”
Assessment: I didn’t ask for a book report and “billions of polygons” is stupid. But the core answer of “a few hundred to a few thousand polygons” is correct, and may even be superior to March!GPT4, which stuck to the lower end of that range.
Conclusion: inconclusive.
Test 4: Rope Burn Puzzle
Prompt: “You have three ropes and some matches. The ropes burn irregularly like fuses when lit at either end. The first rope burns in 48 minutes, the second rope burns in 72 minutes and the third rope burns in 128 minutes. How can you produce a time interval of 61 minutes?”
(For reference: March!GPT4 and June!GPT4’s answers)
Assessment: The fuck did I just read?
It’s hard to judge whether it does better or worse than March!GPT4 or June!GPT4. I’m starting to think this puzzle is simply beyond GPT4’s pay grade. I’ve tried it dozens of times and with many wordings. It does not ever solve it.
It grasps the principle, grasps the underlying method (burning ropes at multiple ends), but it always makes the same mistake—burning the wrong rope, and then trying to weasel out by saying “measure time using some other method.”
Gemini will launch soon. I wonder if it can solve it?
Conclusion: Rope burning puzzles are a common class of interview question. GPT-4 can solve a two-rope variant easily. This three-rope variant is from Varsity Math Week 151. Notably, the answer is also on the internet (and probably in GPT4’s training data)…but it’s in Varsity Math Week 152. Maybe if both the puzzle and the answer were on the same page, GPT4 would solve it. I don’t know how this stuff works.
Conclusion
My tests (for the little they’re worth) show no consistent pattern. Sometimes GPT4 does better than before, sometimes worse.
This is not testing, it’s sheep-entrail reading. I do faintly suspect it’s worse on obscure general knowledge, but I don’t believe that hard enough to bet almost any amount of money.
As I’ve said before, AIs present a fluctuating target. I do not think they have a stable “baseline” ability that remains resilient to prompting differences and stochastic factors. In any event, OpenAI has many dials they can turn behind the scenes.
We’d learn more about this beast over hundreds or thousands of tests. But GPT-4 is too expensive for that to be realistic. OpenAI could really help the community by offering an academic discount—not that weirdos on the internet would qualify, of course!
Lastly, a “good” response is more subjective than I thought. Is it better for a wrong answer to have 500 words or 10 words? Is it better for an AI to try and fail, or to simply give up? When a query has conflicting requirements (“I want a list of all college majors in the US. Do not use more than 10 words.”) what should it do? And when a technically “correct” answer is bad for the user (consider XY problems such as “how do I echo the last three letters of a filename?”—GPT4 flunks this one, by the way), what do we want an AI to do?
GPT4 has changed and will continue to change. We’d be wise to do the same. I will be far less confident in my future predictions. When I say AI has gotten dumb, I might be speaking into a mirror.
2 Comments »
Comments are moderated and may take up to 24 hours to appear.
What I love about the public response, including yours, to AI natural language fortune telling machines: if the small part of humanity that responds to new technology was treated like a chatgpt response to an issue, it would be ignored on the bases of irrationality and bias, deleted, and rebooted :)
I respect your honesty and humility mightily. They are the last differences between AI and humans.
Comment by Mark Osborne — 2023-09-16 @ 21:01
While I’m in the fledgling stages in my appreciation for AI and ChatGPT, I believe that your assessment to look inside the failures of this tool is honorable and useful. Currently, it appears that this use of technology is best used for items not requiring historical accuracy. In light of that comment, it makes me wonder how superfluous it uses are… very good article. I very much enjoyed it.
Comment by LudditeinKS — 2023-09-18 @ 19:28